NEW!
The open-source no-code data pipeline for Amazon Web Services.
Save hundreds of hours of development time. Our Pipeline transforms and loads your data files into a data lake or into a data warehouse such as Snowflake or Redshift, all with no coding.

Simplify your data process and stay flexible
With the idata cloud-based data pipeline you can manage your enterprise data without any coding knowledge. Do you have have a team of developers ? No worries, we can provide you with our source code also.


Simple migration
Create your own Data Pipeline

Centralize all data
“We democratize data and disrupt how your company makes decisions.” T. Fearn
Our Process
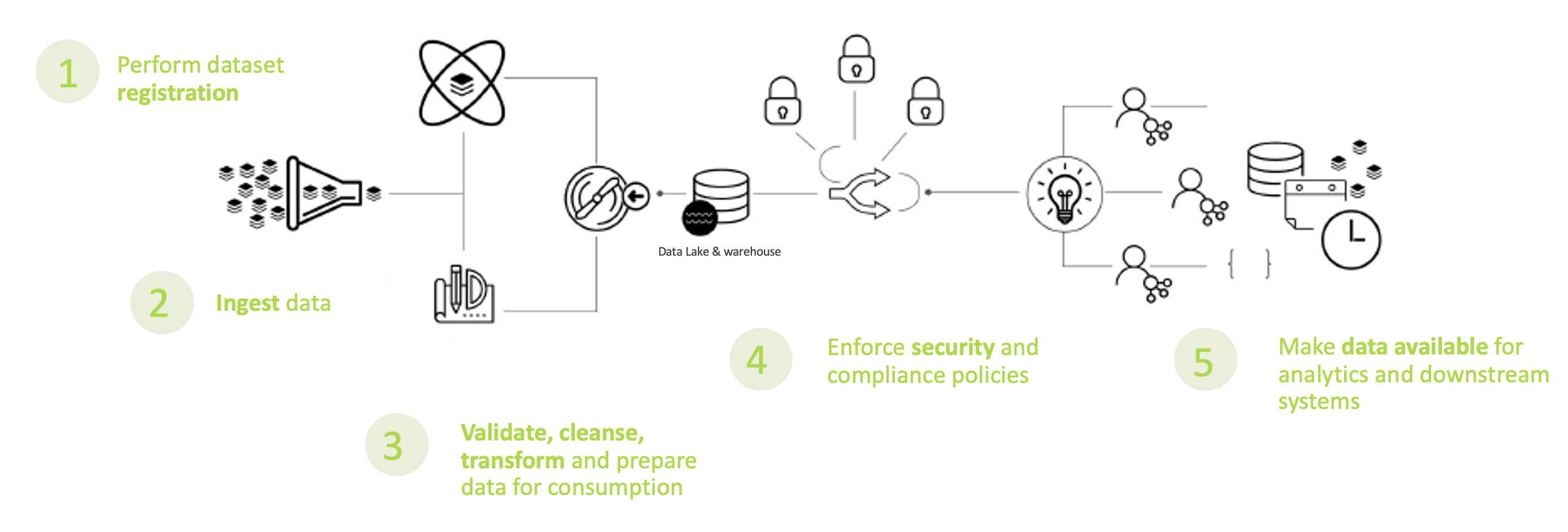
We centralize, validate, cleanse, transform and prepare data to make it available and easily usable for data science and analytics.
Our benefits
Up and running in just a couple of hours.
No coding
No coding is necessary to deal with your data pipeline. Save costs on expensive programmers with skills such as Spark, Scala, Python, …
No code repositories & deployments
Eliminate the need for code repositories and deployments for your data pipeline.
No trial and error
Eliminate the need for code repositories and deployments for your data pipeline.
Automatic notifications
Automatic notifications to downstream consumers such as data engineering teams, reporting systems etc.
Build your own platform
Customize it
Customize it and add your own business logic using Pipeline Triggers.

Tailored Support
Our team will support you and guide you if your enterprise has special requests during and after the migration. We offer extensive technical documentation too.
Other powerful features
Lakehouse technology
The Pipeline uses open-source Delta Lake technology which provides ACID transactions, time-travel queries, upserts and deletes on top of S3 object store.
Dataset validation
Data profiling using data quality configuration rules and data deduplication capabilities.
Data transformation
Employ the use of Javascript, associated with a dataset, to perform your own powerful custom transformations.
Infrastructure as Code (IaC)
The Pipeline can be spun in an hour or less in your AWS account using our IaC code written entirely in Terraform.
Structured, semi-structured and unstructured data
The Pipeline can consume and process basically unlimited types of data (csv, delimited, JSON, XML, PDFs, images, video, …).
AWS Glue Catalog use
The Pipeline uses AWS Glue which automatically enables a large number of AWS services to consume datasets downstream.
Pricing
-
Free trial
Try this product for 14 days for free. There will be no software charges, but AWS infrastructure charges still apply.
-
Subscription
Unit type
ECS Task or EKS PodCost/unit/hour
$5.00