Case Study - Enterprise Data Lake & Pipeline
The Company
This large pension fund invests in a variety of vehicles, including public equities, private equities, real estate, infrastructure and fixed income instruments. As of December 31, 2018, the fund managed over $200 billion USD.
The Challenge
The fund has an initiative to make both internal and external data sources available to the entire organization to speed core services execution and to use data for performing data analytics by investment teams. The approach to data the fund took historically was to implement local solutions that solve individual business needs or manual efforts by each independent team, resulting in a fragmented approach and a large number of silo’d data ponds. Implementation of a data strategy began a few years prior centered around an on-premise approach to centralizing in-house data around a third party product. Subsequently, a canvassing of data related needs across investment departments and core services groups identified a need for a technology capability that provided visibility and timely access to all existing data and allowing for introduction of new datasets with relative ease, along with a data operating model and governance that supported the sharing of data across the fund.
The Solution
The solution was to create a data ecosystem (data lake and data pipeline) that would be central to providing investment departments and service groups across the fund with access to core data domains and new sources of data. Based upon the technical needs to enable the data lake, we envisioned a cloud-based platform that would accommodate different types of data and compute needs that were most relevant to the business – a data pipeline that ingests and normalizes data to a data lake which acts as a central repository, discovery through a data catalog, data access methods to support disparate needs integrated with a cloud compute environment for applications and analytics.
Amazon Web Services (AWS) was chosen as the cloud provider. IData was engaged to drive the process to build and support the AWS technology foundation, security implementation, continuous integration/continuous delivery (CI/CD) pipeline, and create the application stack to support the data lake and ETL ingestion pipeline.
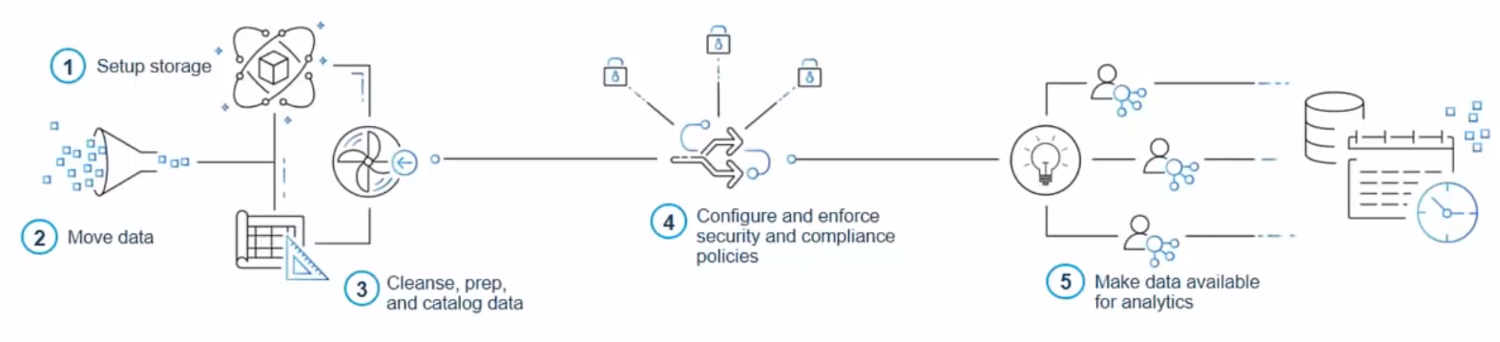
The key elements of the cloud infrastructure, data and compute platform that we created are described below.
Cloud-based Account / Project Structure
The proper root account / sub-account / project structure was implemented to achieve huge gains in productivity, innovation, and cost reduction as the pension fund migrated to the AWS cloud. There are a variety of services and features that allow for flexible control of cloud computing resources and also of the AWS account(s) managing those resources. On the account level, these options are designed to help provide proper cost allocation, agility, and security. A project-based mapping one-to-one to a sub-account structure was implemented. Creating a security relationship between sub-accounts was a key element added to assess the security of cloud-based deployments, centralize security monitoring and management, manage identity and access, and provide audit and compliance monitoring services.
Network Configuration with a Security Backbone
A Transit VPC Solution was implemented as a very useful networking construct. The fund uses this to connect multiple Virtual Private Clouds (VPCs) that might be geographically disparate and/or running in separate accounts, to a common VPC that serves as a global network transit center. This network topology simplifies network management and minimizes the number of connections that are needed to set up and manage.
Implementation of secure VPC endpoints enabled the fund to privately connect VPCs to supported cloud services and VPC endpoint services powered by PrivateLink without requiring an internet gateway, NAT device, or VPN connection. Instances in VPC do not require public IP addresses to communicate with resources in the service. Traffic between the fund VPCs and the other services do not leave the cloud network.
Project-based Implementation with Infrastructure as Code (IaC)
Infrastructure as Code (IaC) was implemented as a method to provision and manage IT infrastructure through the use of source code, rather than through standard operating procedures and manual processes. IaC helps the fund to automate the infrastructure deployment process in a repeatable, consistent manner, also providing the benefit to easily deploy standard infrastructure environments in other regions where the cloud provider operates so they can be used for backup and disaster recovery.
Serverless Compute and Storage
By employing cloud serverless compute and storage, such as Lambdas and object-stores (S3), the fund leverages the ability to build and run applications and services and with infinite elasticity without using physical hardware. In addition, all existing costs associated with managing servers and containers (operating system updates, maintenance updates, image snapshots, backups, restarts, etc.) largely disappeared.
ETL and the Data Pipeline
The data pipeline acts as a utility – a standard suite of data tools that enabled the fund to automate the sourcing, processing, and entitlement of data. Automation of these processes allows data sources to be quickly added and the approach for the cloud data lake then extracted, transformed, combined, validated and loaded (ETL) for further use. The data pipeline is able to simultaneously process multiple data sources at once.
Enterprise Data Lake
The introduction of an enterprise data lake provided a central data repository and access to analytics tools that maximized the value of the data. The enterprise data lake is a centralized repository that allows storage of structured and unstructured data at any scale. Data can be stored as-is, without having to first structure the data, and run different types of analytics – from dashboards and visualizations to big data processing, real-time analytics, and machine learning to guide better decisions.
Data Catalog and Discover-ability
The introduction of a data catalog provided a single searchable glossary of data that is available to the organization, including the data source, definition and entitlements. The data catalog built on top of the data lake allows users to find the data they need and then use it in the tools that they prefer along with ensuring information boundaries and data contracts are not violated.
Application Programming Interface
An Application Program Interface (API) is a set of software routines that allow programs to interact. The use of an API at the pension fund allowed data from the enterprise data lake to be accessed by upstream applications that rely on it. Additionally, the API enabled end users access to data for their individual analytics and modelling needs.
Analyze and Visualize Data
Through self-discovery of data resident in the enterprise data lake through the data catalog, individuals are able to access data based on their entitlements. For low technology use cases, end users are able to upload datasets into Excel or tools such as Tableau, or alternatively, the API allows data to be integrated with programs coded in Python, Scala, Java, R, etc.
Sandbox for Experimentation
To support innovation, the data lake includes a sandbox environment that provides the functionality of the enterprise data lake but allows one to easily introduce new datasets and technologies for experimentation.
Flexibility of Architecture
Unlike traditional technical approaches for data warehousing which are inflexible in terms of data schemas, technical capabilities and tools, the cloud based approach allows flexibility on all of these fronts. Fit for purpose cloud based data tools and technologies can be incorporated with relative ease as needs get identified.
Benefits
The creation of an enterprise data lake had substantial benefits. Historically, the fund had data that existed in individual business teams or systems. Providing access to this data required point-to-point solutions and significant time was spent preparing and reconciling data by each team who uses it. Additionally, teams were not aware of data that existed within the organization. The enterprise data lake enabled fund teams to capitalize on the value in data, by bringing together internal and external datasets in a single place as well as eliminating redundant reconciliations by using the same dataset. This value grows as new data sets are added. This easy access to a broad set of data empowers users to innovate the way the fund constructs and measures portfolios, manages assets, and thinks about risk.
By leveraging the data catalog, investment groups at the fund can now easily discover, access and perform analytics on hundreds of datasets. After discovery, analysts can access data directly via an API into their environment, or they can leverage sophisticated scalable cloud based analytics software, such as Spark based services, to perform intense algorithms against multiple datasets. This greatly speeds analytics and increases its use in investment decision making.
The implementation of a Continuous Integration/Continuous Deliver (CI/CD) approach to cloud development and deployment, the fund can deliver new software features in hours or days instead of months. Smaller code changes are simpler (more atomic) and have fewer unintended consequences. Upgrades introduce smaller units of change and are less disruptive. The products improve rapidly through fast feature introduction and fast turn-around on feature changes. End-user involvement and feedback during continuous development leads to usability improvements. You can add new requirements based on customer’s needs on a daily basis.
IData’s Enterprise Data Pipeline runs exclusively on AWS
